2025-07-01 09:55 6017 прочитано
 The exponential growth of data-driven business decisions has made web scraping at scale a critical capability for modern enterprises. However, scaling data collection operations presents unique challenges, particularly in maintaining anonymity, avoiding detection, and ensuring reliable data quality while managing costs effectively. This comprehensive case study examines how organizations can safely scale web data collection using proxy infrastructure, drawing from real-world implementations and industry best practices.
The exponential growth of data-driven business decisions has made web scraping at scale a critical capability for modern enterprises. However, scaling data collection operations presents unique challenges, particularly in maintaining anonymity, avoiding detection, and ensuring reliable data quality while managing costs effectively. This comprehensive case study examines how organizations can safely scale web data collection using proxy infrastructure, drawing from real-world implementations and industry best practices.The Critical Need for Proxy-Enabled Web Scraping
Web scraping has evolved from a simple data extraction tool to a sophisticated operation that often requires processing millions of pages across diverse sources. One of the most common challenges encountered when web scraping is scaling, where traditional single-IP approaches quickly become inadequate. Modern websites employ increasingly sophisticated anti-bot measures, including rate limiting, IP blocking, browser fingerprinting, and CAPTCHA challenges.
The fundamental issue lies in the detection patterns that emerge from high-volume requests. Websites can easily identify and block activities when thousands of requests originate from the same IP address, making proxy rotation essential for maintaining operational continuity. Proxies solve this problem by distributing traffic through different IPs, enabling anonymity and access to restricted content.
Architecture for Scalable Proxy Infrastructure
Distributed Scraping Framework
Distributed scraping involves breaking down the scraping workload across multiple machines or nodes, allowing for parallel processing and faster data collection. The architecture typically consists of several key components:
Master Node: Coordinates tasks and distributes URLs across the network. This central controller manages the overall scraping workflow, handles task prioritization, and monitors system health.
Worker Nodes: Execute the actual scraping tasks, each equipped with its own proxy configuration. These nodes can be scaled horizontally based on demand, with each worker handling specific portions of the target data.
Message Queue: Manages communication between components using systems like Redis or Kafka. This ensures reliable task distribution and handles retry mechanisms for failed requests.
Proxy Management Layer: Having a robust proxy management system in place is critical if you want to be able to reliably scrape the web at scale. This layer handles proxy rotation, health monitoring, and automatic failover.
Mathematical Optimization of Distributed Systems
For a distributed scraping system with
N nodes and U total URLs, optimal resource allocation follows the formula:URLs_per_node = U / N
If each node can handle
C concurrent requests per second, the estimated time T for completion becomes:T = (URLs_per_node) / C
This linear scaling relationship demonstrates that by increasing the number of nodes N, the overall scraping time can be reduced linearly, making distributed architecture essential for large-scale operations.
Proxy Types and Strategic Selection
Residential vs. Datacenter Proxies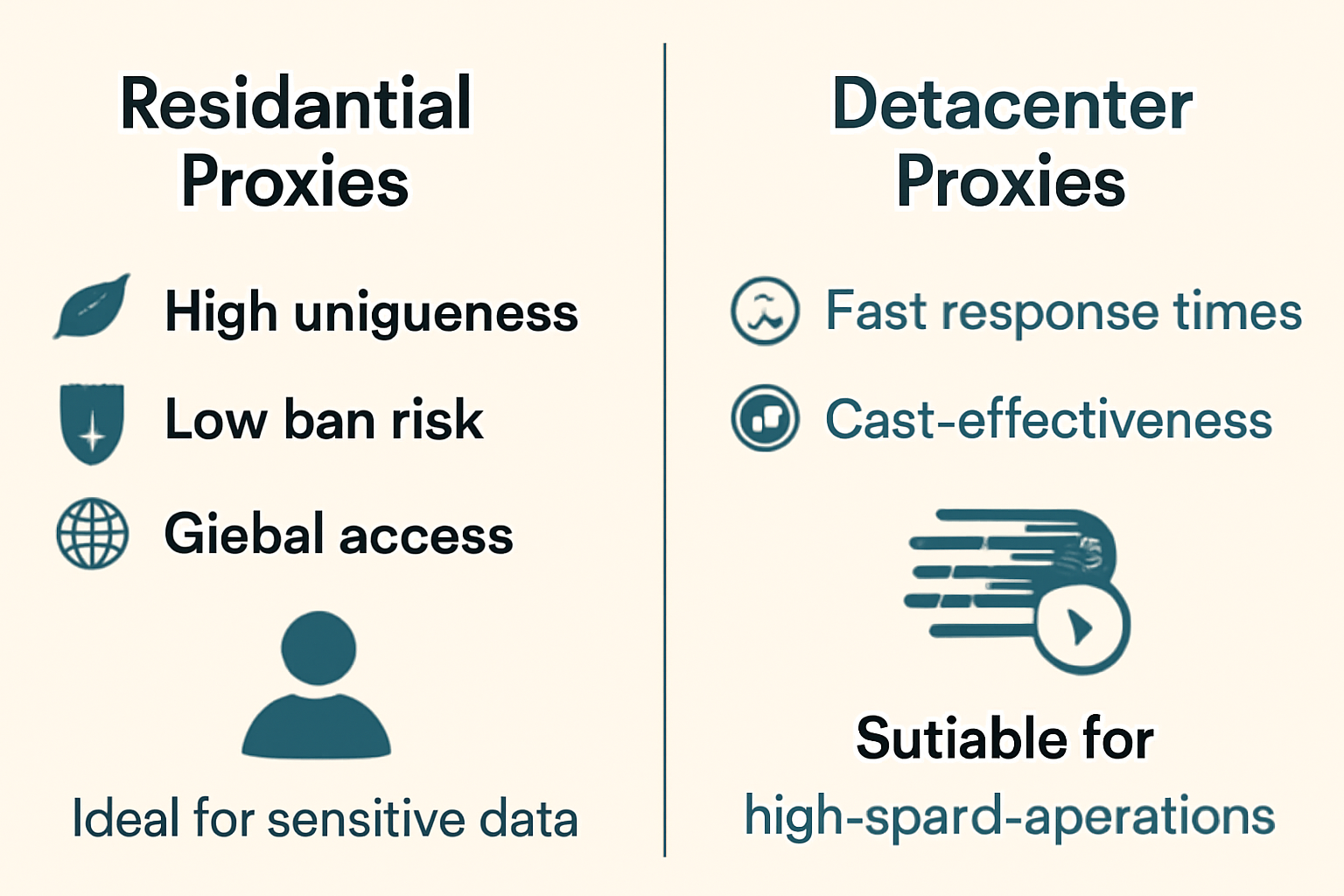
The choice between proxy types significantly impacts both performance and cost-effectiveness. Residential proxies offer rotating IPs for anonymity and real-user behavior, while datacenter proxies provide stable, unique IPs for speed and reliability.
Residential Proxies provide several advantages:
-
High uniqueness, resembling actual users
-
Low ban risk due to unique IPs
-
International access with a variety of regional IPs
-
Ideal for sensitive data extraction where detection avoidance is critical
Datacenter Proxies excel in different scenarios:
-
Fast response times and cost-effectiveness
-
Limited to the proxy server's geographic location
-
Higher ban risk, with subnet bans affecting many IPs
-
Suitable for simple websites and high-speed operations
Proxy Rotation Strategies
Proxy server rotation is a process of automatically assigning different IP addresses to a new web scraping session. Effective rotation strategies include:
Time-based rotation: Switching proxies at predetermined intervals to maintain anonymity
Request-based rotation: Rotating proxies automatically change the IP address after each request, ensuring that no single IP is used repeatedly
Failure-based rotation: Immediately switching proxies when encountering blocks or errors
Advanced Anti-Detection Techniques
Browser Fingerprinting Countermeasures
Modern web scraping operations must address sophisticated detection methods beyond simple IP tracking. Websites can check for certain properties that are true for headless browsers (e.g., navigator.webdriver being true). Effective countermeasures include:
User-Agent Rotation: Change the default user-agent string to a common user-agent of a popular browser
WebDriver Property Modification: Using JavaScript injection to modify telltale browser properties
Human Behavior Simulation: Mimic human interaction by implementing random delays between requests to mimic human browsing behavior
CAPTCHA and Challenge Response Systems
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is a security mechanism designed to distinguish real users from automated bots. Advanced scraping operations increasingly rely on automated CAPTCHA solving services, which provide:
-
High accuracy in solving various types of CAPTCHAs
-
Speed designed to solve CAPTCHAs quickly, ensuring minimal disruption
-
Easy integration through simple APIs
Performance Monitoring and Optimization
Real-Time Monitoring Systems
Effective scaling requires comprehensive monitoring of scraping operations. ScrapeOps automatically logs and ships your scraping performance stats, so you can monitor everything in a single dashboard. Key metrics include:
Success Rates: Tracking the percentage of successful requests versus failures
Response Times: Monitoring average and peak response times across different proxies
Error Patterns: The ScrapeOps SDK logs any Warnings or Errors raised in your jobs and aggregates them on your dashboard
Cost Optimization: ScrapeOps checks pages for CAPTCHAs & bans, and the data quality of every item scraped
Data Quality Validation
Real-time data quality refers to the process of ensuring the accuracy, consistency, and reliability of data as it is captured and processed in real-time. This includes:
Schema Validation: Ensuring data adheres to predefined schemas and catching discrepancies early
Anomaly Detection: Use anomaly detection techniques to identify unusual patterns that could indicate data quality issues
Duplicate Prevention: Implement logic to identify and handle duplicate data entries
Cost Optimization Strategies
Proxy Usage Optimization
Optimizing proxy costs involves maximizing the utility of the proxies purchased, ensuring that there is minimal waste. Effective strategies include:
Traffic Analysis: Track your data usage over time. Identifying peak times and heavy-traffic periods can help in selecting proxies that offer the most value
Proxy Type Selection: Not all proxy types are suitable for every task. By evaluating the nature of your tasks and the frequency of your requests, you can choose the most appropriate proxy type
Bulk Pricing: Some providers offer bulk discounts on large proxy plans with 100+ IPs, reducing the per-proxy price
Resource Allocation Optimization
Large-scale operations benefit from strategic resource allocation. One practitioner reported: "Each node is an 80 core arm server from hetzner for about 200 euro/mo. That's why I like playwright because it comes with an Arm64 docker image". This demonstrates the importance of choosing cost-effective hardware that matches the specific requirements of web scraping operations.
Legal and Compliance Considerations
GDPR and Data Protection
Organizations using web scraping, therefore, must ensure they have a lawful basis under the GDPR for processing both ordinary and special categories of personal data. Key compliance requirements include:
Lawful Basis: Any processing of personal data must be justified by a legitimate legal basis
Data Minimization: Collecting only the data necessary for the specific purpose
Consent Considerations: Consent is unlikely to serve as a valid legal basis for web scraping, as it requires the informed and voluntary agreement of the individuals whose data is collected
Ethical Scraping Practices
The first rule of scraping the web is: do not harm the website. Best practices include:
Rate Limiting: Limit the number of concurrent requests to the same website from a single IP
Robots.txt Compliance: Always check the website's robots.txt file to follow guidelines on what can be scraped
Off-Peak Scheduling: If possible it is more respectful if you can schedule your crawls to take place at the website's off-peak hours
Implementation Roadmap
Phase 1: Infrastructure Setup
-
Establish distributed architecture with master-worker node configuration
-
Implement proxy management system with health monitoring
-
Set up message queuing system for reliable task distribution
Phase 2: Proxy Integration
-
Deploy hybrid proxy strategy combining residential and datacenter proxies
-
Implement rotation mechanisms based on time, requests, and failure patterns
-
Configure anti-detection measures including user-agent rotation and fingerprinting countermeasures
Phase 3: Monitoring and Optimization
-
Deploy real-time monitoring dashboard for performance tracking
-
Implement data quality validation with anomaly detection
-
Establish cost optimization protocols for proxy usage efficiency
Conclusion
Scaling web data collection safely with proxies requires a comprehensive approach that balances technical sophistication with operational efficiency. The success of organizations like Advantage Solutions demonstrates that with the right proxy infrastructure and management strategies, it's possible to scale data collection operations while maintaining reliability and cost-effectiveness.
The key to successful implementation lies in understanding that proxy management must be a priority when scaling web scraping operations. By implementing distributed architectures, leveraging hybrid proxy strategies, and maintaining rigorous monitoring and compliance protocols, organizations can build robust data collection capabilities that scale with their growing needs.
As the digital landscape continues to evolve, the ability to safely and efficiently collect web data at scale will remain a critical competitive advantage. Organizations that invest in proper proxy infrastructure and follow best practices will be better positioned to leverage the full potential of web-based data sources while maintaining operational integrity and legal compliance.